Chapter 5: Querying Information¶

Credit: xkcd
TL;DR: Querying data is at the heart of information retrieval, whether we query for data or for documents that contain data.
Query languages¶
Database operations can be summarized with the acronym CRUD: create, read, update and delete.
From an information standpoint, the main focus is reading from the database. Most often though, we do not read directly, as this is not possible (not all databases can be browsed), or practical (we get too much information). Instead, reading databases is usually done through querying, for which we use query languages.
Actually, query languages surpass databases. Formally, query languages can be classified as database query languages versus information retrieval query languages. The difference is that a database query language attempts to give factual answers to factual questions, while an information retrieval query language attempts to find documents containing information that is relevant to an area of inquiry.
For the former we will discuss SQL, for the latter CQL.
Database querying: SQL/SQLite¶
SQL is a technology that is probably new to most of you. Unlike RDF, which some libraries seem hesitant to adopt, SQL is ubiquitous, including outside of libraries. Moreover, SQL has for instance heavily influenced the aforementioned CQL, and also SPARQL, the query language for RDF. So knowing SQL will open many doors.
SQL is the query language for RDBMS, which are most often implemented in a client-server database engine. So for you to use SQL you would need a connection to a SQL database server, i.e. something like MySQL or PostgreSQL, which you can see, for instance, running on my local machine like so:
tdeneire@XPS-13-9370:~/tmp$ ps -ef | grep postgres
postgres 1258 1 0 07:01 ? 00:00:00 /usr/lib/postgresql/12/bin/postgres -D /var/lib/postgresql/12/main -c config_file=/etc/postgresql/12/main/postgresql.conf
postgres 1286 1258 0 07:01 ? 00:00:00 postgres: 12/main: checkpointer
postgres 1287 1258 0 07:01 ? 00:00:00 postgres: 12/main: background writer
postgres 1288 1258 0 07:01 ? 00:00:00 postgres: 12/main: walwriter
postgres 1289 1258 0 07:01 ? 00:00:00 postgres: 12/main: autovacuum launcher
postgres 1290 1258 0 07:01 ? 00:00:00 postgres: 12/main: stats collector
postgres 1291 1258 0 07:01 ? 00:00:00 postgres: 12/main: logical replication launcher
However, there is also a very good standalone alternative, called SQLite.
Simply said SQLite is just a single file, but you can query it just like a SQL database server. Moreover, you can access SQLite databases from many programming languages (C, Python, PHP, Go, …), but you can also handle them with GUIs like DB Browser, which makes them also very suitable for non-technical use.
If you want to know more about SQLite, I wrote this blog about why it is the most widely-used database in the world…
SQL queries¶
There are some minute differences between SQL syntax and the SQLite dialect, but these so small they can be neglected.
SQL queries always take the same basic form: we select data from a table (mandatory), where certain conditions apply (optional). We can use join (in different forms) to add one or more tables to the selected table:
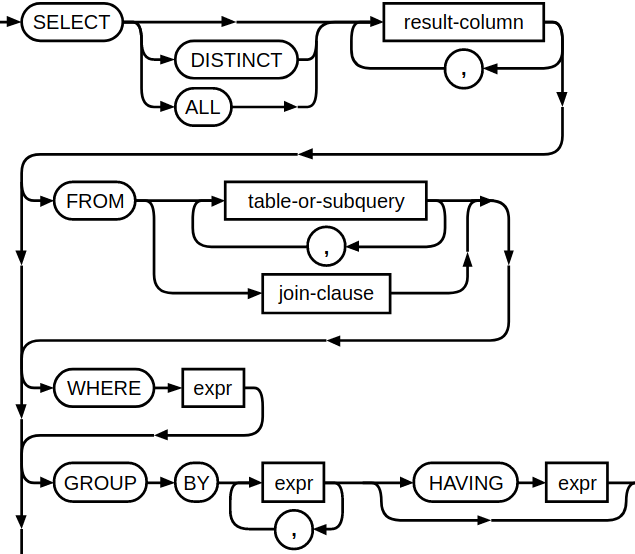
This SQL cheat sheet also offers a great summary.
Let’s look at a concrete example.
Python sqlite3¶
Python’s standard library contains the module sqlite3 which offers an API for a SQLite database. (We will discuss API’s in general later in this chapter).
For example, let’s launch some SQL queries on a SQLite database of STCV, which is the Short Title Catalogue Flanders, an online database with extensive bibliographical descriptions of editions printed in Flanders before 1801. This database is available as part of the Anet Open Data. A version of it is available in this repo under data.
import os
import sqlite3
# To use the module, you must first create a Connection object that represents the database
conn = sqlite3.connect(os.path.join('data', 'stcv.sqlite'))
# Once you have a Connection, you create a Cursor object
c = conn.cursor()
# To perform SQL commands you call the Cursor object's .execute() method
query = """
SELECT DISTINCT
author.author_zvwr,
title.title_ti,
impressum.impressum_ju1sv FROM author
JOIN
title ON author.cloi = title.cloi
JOIN
impressum ON title.cloi = impressum.cloi
ORDER BY
author.author_zvwr DESC
"""
c.execute(query)
# Call fetchall() to get a list of the matching rows
data = [row for row in c.fetchall()]
# Print sample of result
for row in data[50:60]:
print(row)
# Close the connection when you're done
conn.close()
('Ægidius de Lallaing', 'Den troost der scrvpvlevse; dat is: Gheestelyck medecijn-boecksken, in-houdende vele troostelijcke remedien teghen de [...] scrupuleusheyt', '1647')
('Ægidius de Coninck', 'Commentariorvm ac dispvtationvm in Vniuersam doctrinam D. Thomæ De sacramentis et censvris tomi dvo', '1624')
('Ægidius de Coninck', 'Responsio ad dissertationem impvgnantem absolutionem moribundi sensibus destituti', '1625')
('Ægidius de Coninck', 'Commentariorvm ac dispvtationvm in vniuersam doctrinam D. Thomæ de sacramentis et censvris tomi dvo', '1619')
('Ægidius de Coninck', 'Commentariorvm ac dispvtationvm in vniuersam doctrinam D. Thomæ de sacramentis et censvris tomi dvo', '1616')
('Ægidius de Coninck', 'De moralitate, natvra, et effectibvs actvvm svpernatvralivm in genere. Et fide, spe, ac charitate, speciatim. Libri quatuor', '1623')
('Ægidius de Coninck', 'De actibvs svpernatvralibvs in genere', '1623')
('Ægidius de Coninck', 'Dispvtationes theologicæ de sanctissima trinitate et divini verbi incarnatione', '1645')
('Ægidius Perrinus', 'Sextvs decretalivm liber', '1573')
('Ægidius Perrinus', 'Institvtionvm, sive Primorum totius iurisprudentiæ elementorum libri qvatvor', '1575')
Becoming fully versed in SQL is beyond the scope of this course. In this context, it is enough to understand the capabilities of SQL and the basic anatomy of a SQL query. This will help you to better understand RDBM systems as a whole or learn new querying technologies, such as the aforementioned SPARQL, which is effectively a variant of SQL:
Consider this example:
SELECT DISTINCT
?resource, ?name, ?birthDate, ?deathDate
WHERE {
?resource rdfs:label "Hugo Claus"@en;
rdfs:label ?name;
rdf:type dbo:Person
OPTIONAL {?resource dbp:birthDate ?birthDate}.
OPTIONAL {?resource dbp:deathDate ?deathDate}
FILTER(?name = "Hugo Claus"@en)
}
Execute this query against the DBPedia SPARQL endpoint.
Information retrieval querying: CQL/SRU¶
Contextual query language or CQL is an example of an information retrieval query language. According to Wikipedia:Contextual_Query_Language
Contextual Query Language (CQL), previously known as Common Query Language, is a formal language for representing queries to information retrieval systems such as search engines, bibliographic catalogs and museum collection information. (…) its design objective is that queries be human readable and writable, and that the language be intuitive while maintaining the expressiveness of more complex query languages. It is being developed and maintained by the Z39.50 Maintenance Agency, part of the Library of Congress.
Querying with CQL operates via SRU - Search/Retrieve via URL, which is an XML-based protocol for search queries.
You can find the full specifications for CQL and SRU at the Library of Congress website, what is offered here is only the basics.
SRU¶
SRU (Search/Retrieve via URL) is a standard search protocol for Internet search queries. In the context of libraries, SRU is mainly used for search and retrieval of bibliographic records from the catalog.
A valid SRU request always contains a reference to the SRU “version” and an “operation”, optionally enriched with “parameters”.
The explain operation allows a client to retrieve a description of the facilities available at an SRU server. It can then be used by the client to self-configure and provide an appropriate interface to the user. The response includes list of all the searchable indexes.
e.g. https://data.cerl.org/thesaurus/_sru?version=1.2&operation=explain
The searchRetrieve operation is the main operation of SRU. It allows the client to submit a search and retrieve request for matching records from the server. This operation needs to be combined with the query parameter
e.g. https://data.cerl.org/thesaurus/_sru?version=1.2&operation=searchRetrieve&query=erasmus
Note the tag <srw:numberOfRecords>. Most SRU servers will not give you the entire response in one go. You can use the parameters &startRecord= and &maximumRecords= to harvest the whole result in chunks. For instance:
http://sru.gbv.de/hpb?version=2.0&operation=searchRetrieve&query=lipsius
->
CQL¶
A SRU search statement, i.e. the &query= part, is expressed in CQL syntax.
The simplest CQL queries are unqualified single terms:
Queries may be joined together using the three Boolean operators, and, or and not. We use spaces, or rather their URL encoded version %20 to separate CQL words:
The queries discussed so far are targeted at whole records. Sometimes we need to be more specific, and limit a search to a particular field of the records we’re interested in. In CQL, we do this using indexes. An index is generally attached to its search-term with an equals sign (=). Indexes indicate what part of the records is to be searched - in implementation terms, they frequently specify which index is to be inspected in the database. For information about which specific indexes you can use, use the explain operation:
SRU also allows other relations than equality (=) which we have just used (e.g. publicationYear < 1980) and pattern matching:
Example: CERL thesaurus¶
Let’s have a more detailed look at one of the examples used frequently in the above. This source that supports SRU/CQL is the CERL (Consortium of European Research Libraries), which is responsible for the CERL Thesaurus, containing forms of imprint places, imprint names, personal names and corporate names as found in material printed before the middle of the nineteenth century - including variant spellings, forms in Latin and other languages, and fictitious names.
Below is an example of how to query this source with SRU/CQL from Python:
import urllib.parse
import urllib.request
import urllib.error
CERL_SRU_PREFIX = "https://data.cerl.org/thesaurus/_sru?version=1.2&operation=searchRetrieve&query="
def clean(string: str) -> str:
"""
Clean input string and URL encode
"""
string = string.strip()
string = string.casefold()
string = urllib.parse.quote(string)
return string
def query_CERL(search: str) -> bytes:
"""
Query CERL thesaurus, return response or exit with errorcode
"""
cql_query = clean(search)
url = CERL_SRU_PREFIX + cql_query
try:
with urllib.request.urlopen(url) as query:
return query.read()
except urllib.error.HTTPError as HTTPerr:
exit(HTTPerr.code)
except urllib.error.URLError as URLerr:
exit(str(URLerr))
user_input = input()
print(str(query_CERL(user_input)[0:1000]) + "...")
b'<?xml version="1.0"?>\r\n<srw:searchRetrieveResponse xmlns:srw="http://www.loc.gov/zing/srw/" xmlns:diag="http://www.loc.gov/zing/srw/diagnostic/">\r\n<srw:version>1.2</srw:version>\r\n<srw:numberOfRecords>51</srw:numberOfRecords>\r\n<srw:records>\r\n\r\n <srw:record>\r\n <srw:recordSchema>http://sru.cerl.org/schema/ctas/1.1/</srw:recordSchema>\r\n <srw:recordPacking>xml</srw:recordPacking>\r\n <srw:recordIdentifier>cnp00605296</srw:recordIdentifier>\r\n <srw:recordData>\r\n \r\n \r\n <record id="cnp00605296" type="personalName" xmlns="http://sru.cerl.org/ctas/dtd/1.1"><info><display>Lipsius, Jacob</display></info><nameForms><headingForm name="full">Jacob Lipsius</headingForm><headingForm name="inverted">Lipsius, Jacob</headingForm><variantForm name="full">Jacobus Lipsius</variantForm><variantForm name="inverted">Lipsius, Jacobus</variantForm><variantForm name="full">Jakob Lipsius</variantForm><variantForm name="inverted">Lipsius, Jakob</variantForm></nameForm'...
APIs¶
An SRU server is an example of a web API, or Application Programming Interface.
Non-technical users mostly interact with data through a GUI or Graphical User Interface, either locally (e.g. you use DBbrowser to look at an SQLite database) or on the web (e.g. you use Wikidata’s web page). However, when we try to interact with this data from a machine-standpoint, i.e. in programming, this GUI is not suitable. We need an interface that is geared towards computers. So we use a local API (e.g. Python’s sqlite3 module) or web API (e.g. Wikidata’s Query Service) to get this data in a way that can be easily handled by computers.
In this way, an API is an intermediary structure, which has a lot of benefits. Wouldn’t it be nicer to have direct access to a certain database? In a way, yes, but this would also cause problems. There are many, many different database architectures, but API architectures are generally quite predictable. They are often based on well-known technologies like JSON or XML, so you don’t have to learn a new query language. Moreover, suppose Wikidata changes their database. All of your code that uses the database would need to be rewritten. By using the API intermediary structure Wikidata can change the underlying database, but make sure their API still functions in the same way as before.
There are lots of free web APIs out there. The NASA API, for instance, is quite incredible. For book information there is OpenLibrary. Or this Evil Insult Generator, if you want to have some fun! You can find an extensive list of free APIs here.
Exercise: Europeana Entities API¶
For this exercise you will be using the JSON data made available through the Europeana Entities API, which allows you to search on or retrieve information from named entities. These named entities (such as persons, topics and places) are part of the Europeana Entity Collection, a collection of entities in the context of Europeana harvested from and linked to controlled vocabularies, such as GeoNames, DBPedia and Wikidata.
It is advisable to read the API’s documentation first.
Task¶
The task is simple. Write a Python script that prompts for user input of a named entity, query the API for that entity, parse the results and print them on standard output.
Some tips:¶
You can use the key
wskey=apidemofor your API request.A good Python library to access URLs is
urllib, an alternative (which is not in the standard library) isrequests.Think about what we have seen already about standardizing/normalizing search strings, but take this to the next level.
Try to anticipate what can go wrong so the program doesn’t crash in unexpected situations.
Test your application with the following search strings:
Erasmus,Justus LipsiusandDjango Spirelli.